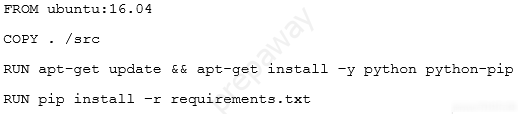
The requirement is reliance testing (recovery from failure )while maintaining 99.9 availability (SLA)
Let's go with elimination.
A. Capture existing users input, and replay captured user load until autoscale is triggered on all layers. At the same time, terminate all resources in one of the zones
>> We are overkilling resilience testing by entering the boundary of DR hence will eliminate this option.
B. Create synthetic random user input, replay synthetic load until autoscale logic is triggered on at least one layer, and introduce ג€chaosג€ to the system by terminating random resources on both zones
>> This option takes care of the requirement of testing. Is a patter used by org like Netflix chaos monkey).
C. Expose the new system to a larger group of users, and increase group size each day until autoscale logic is triggered on all layers. At the same time, terminate random resources on both zones
>> Next quarter your user going to increase, but how are you going to get more users to test, this option is not feasible hence eliminating.
D. Capture existing users input, and replay captured user load until resource utilization crosses 80%. Also, derive estimated number of users based on existing userג€™s usage of the app, and deploy enough resources to handle 200% of expected load
>> The failure is not necessary from CPU utilization, even the hardware can fail under load. Blanket provisioning is not the way to go hence eliminating.
Hence B is correct answer.